Parallel Planning and Tasks: Managing 2-3 Agents Simultaneously
In Lesson 1, you set up 3 independent specifications in separate worktrees. Now comes the power move: running planning and task generation in parallel. You're learning to manage 2-3 agents' planning simultaneously—a skill that becomes essential when scaling to 10-15 parallel agent workflows.
The key insight? With a shared constitution, all 3 planning sessions will maintain consistent quality without needing synchronized meetings. Time that would have been spent in coordination gets spent on actual planning. This lesson teaches you to orchestrate parallelization safely and measure its value.
Review: Your 3 Specs
Before running anything in parallel, let's solidify what you built in Lesson 1. You created three specifications for an Assignment Grader:
- feature-001-upload: Students upload assignments (file validation, storage)
- feature-002-grade: Grading logic and scoring (apply rubric, calculate scores)
- feature-003-feedback: Generate and display feedback (based on grades, shown to students)
Each spec is independent yet has some dependencies:
- feature-002 (grade) depends on uploaded assignments from feature-001 (upload)
- feature-003 (feedback) depends on grades from feature-002
- Features 001 and 002 can start in parallel, Feature 003 waits for both
This is a realistic decomposition. Real systems don't have perfectly isolated components. The question is: how well did you identify these dependencies in your specifications?
Let's visualize it:
┌─────────────┐
│ feature-001 │
│ (upload) │
└──────┬──────┘
│ provides: assignments
│
▼
┌─────────────────┐
│ feature-002 │
│ (grade) │
└──────┬──────────┘
│ provides: scores
│
▼
┌─────────────────┐
│ feature-003 │
│ (feedback) │
└─────────────────┘
The shared constitution (with standards for data formats, error handling) is the glue that keeps all three aligned without constant synchronization. This is what enables parallelization.
Pause and Reflect: Look at your three specifications. Can you identify:
- Where each feature depends on another?
- What data formats must be agreed upon between features?
- Where the shared constitution prevents misalignment?
Running Parallel Planning
Now you're ready to run three planning sessions simultaneously. This is where time savings become dramatic.
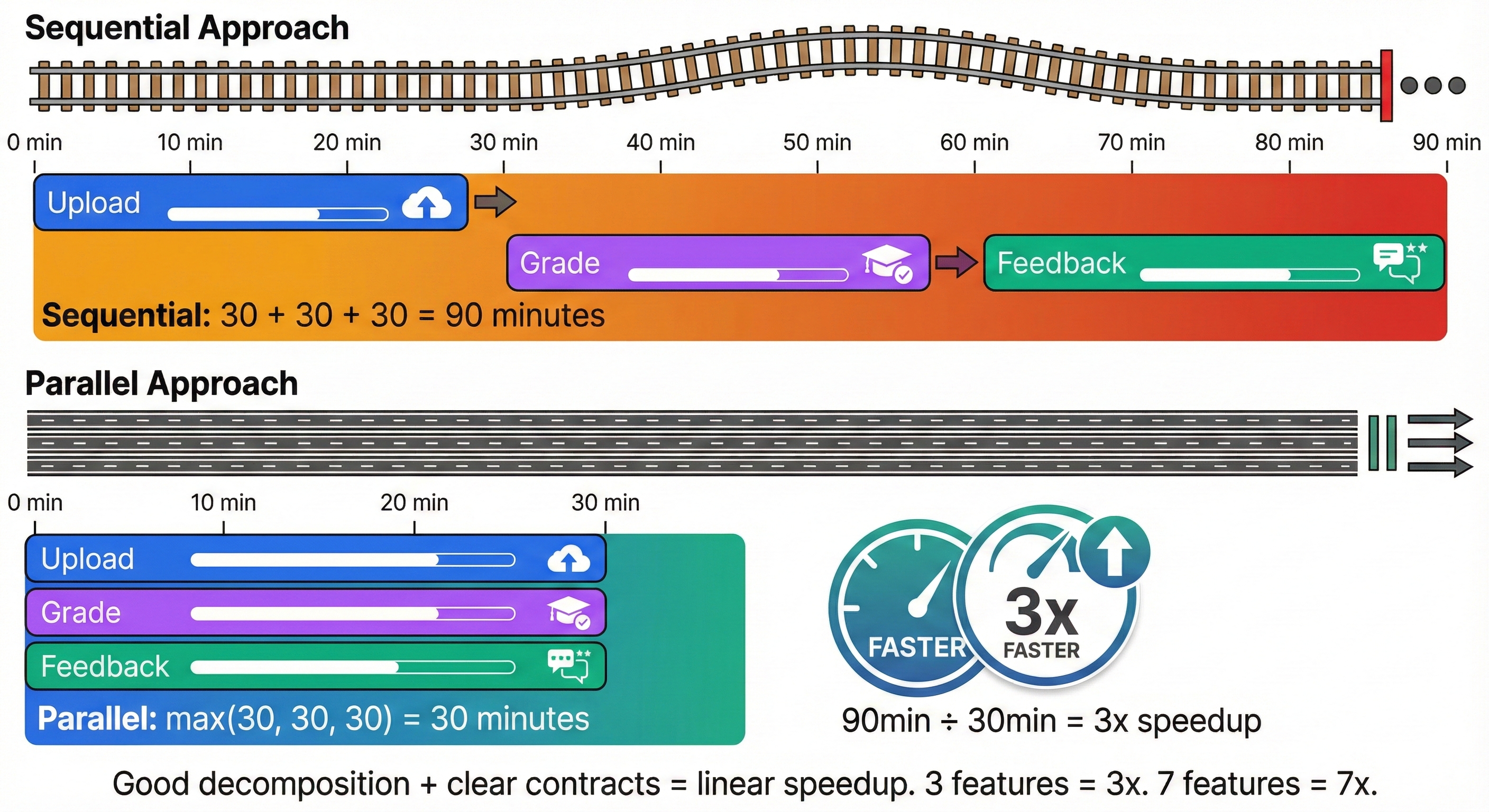
The Sequential Baseline
If you ran these sequentially, the timeline looks like:
Phase 1: Plan feature-001 (upload) 20 minutes
Phase 2: Plan feature-002 (grade) 20 minutes
Phase 3: Plan feature-003 (feedback) 20 minutes
─────────────────────────────────────────────────
Total: 60 minutes
The Parallel Reality
Running all three simultaneously:
Time: 0m 20m
│ │
Session1│ Plan feature-001 (upload) ────┤
Session2│ Plan feature-002 (grade) ─────┤
Session3│ Plan feature-003 (feedback) ──┤
│ │
─────────────────────────────────────────────────
Total: 20 minutes
(instead of 60)
You save 40 minutes—not because planning is faster, but because time is no longer sequential.
How to Execute
Open 3 terminal windows or tabs, each in a different worktree.
Tip: Most terminal applications support tabs or split panes. Use whatever works best for you. Tools like tmux, iTerm2, or VS Code's integrated terminal all work fine.
Navigate each terminal to its worktree and run the command:
Terminal 1:
cd grader-upload
/sp.plan
Terminal 2:
cd grader-grade
/sp.plan
Terminal 3:
cd grader-feedback
/sp.plan
Do this quickly, one after the other. Because the commands are non-blocking (they're running subagents in the background), all three will execute in parallel. After about 20 minutes, all three will complete.
Key Observation: Notice that you're not coordinating these sessions. You're not waiting for feature-001's plan to complete before planning feature-002. The shared constitution ensures that both agents will make aligned decisions—because they're both following the same standards, the same definition of "good", the same API contract patterns.
This is the first proof that decomposition works: if your specifications truly are independent, planning them in parallel will not produce conflicts. If they do conflict later, it means your decomposition had hidden dependencies.
💬 AI Colearning Prompt
"How does a shared constitution prevent quality drift when 3 AI agents plan features in parallel? What would happen without constitutional alignment?"
Evaluating Plan Quality as a Decomposition Indicator
After 20 minutes, you have 3 plans. The real skill is reading what they tell you about your decomposition quality.
The Rubric: Good vs Bad Decomposition
Compare your three plans using this rubric:
| Quality Indicator | Good Decomposition | Bad Decomposition |
|---|---|---|
| Plan length | 2-4 pages per feature | <1 page (underspecified) OR 10+ pages (too complex) |
| Complexity | Balanced across features | One feature much larger than others |
| Tasks count | 10-20 specific tasks per feature | <5 tasks (vague) OR 50+ tasks (too granular) |
| Dependencies | Explicitly listed; minimal cross-feature | Circular, unclear, or many implicit dependencies |
| Integration points | Clearly marked (e.g., "Depends on User ID from feature-001") | Buried in text; hard to identify |
Example: Evaluating Your Three Plans
Let's say your three plans came back with these metrics:
feature-001 (upload):
- Length: 2.5 pages ✓
- Tasks: 12 ✓
- Dependencies: 0 (foundational) ✓
→ Good
feature-002 (grade):
- Length: 2.8 pages ✓
- Tasks: 15 ✓
- Dependencies: 1 (depends on upload format from feature-001) ✓
→ Good
feature-003 (feedback):
- Length: 3.2 pages ✓
- Tasks: 18 ✓
- Dependencies: 2 (depends on grades from feature-002, assignment metadata from feature-001) ✓
→ Good
All three features have balanced complexity. If one feature had 12 pages and 45 tasks, that would signal the decomposition was too ambitious and should be split further.
A plan that's 12 pages signals that the decomposition was poor. At 7-9 agent scale, bad decomposition becomes unmanageable. Imagine trying to run 15 planning sessions where half of them result in 12-page complexity avalanches. You'd spend more time coordinating across complex dependencies than you saved through parallelization.
Reading Plan Quality as a Signal
Use these rules of thumb:
- Balanced complexity (plans within 1-2 pages of each other) = Good decomposition
- One plan is 3-4x larger than others = Hidden complexity; refactor
- More than 3-4 cross-feature dependencies per plan = Too interconnected; redivide
- Explicit integration contracts (e.g., "Expects JSON payload with user_id from feature-001") = Good
- Vague integration (e.g., "Will work with auth system") = Bad; go back to spec
Exercise 3: Evaluate Your Plans
- Open all three plans side-by-side
- For each plan, measure:
- Length (page count or line count)
- Number of distinct tasks
- Number of cross-feature dependencies
- Calculate the ratio: is the largest plan >2x the smallest?
- List all integration points explicitly
- Document: Does this decomposition match "good" or "bad" indicators?
If you find bad indicators, note them—you'll likely need to refactor your decomposition before moving to implementation.
🎓 Expert Insight
In AI-native development, plan length and complexity are early signals of decomposition quality. You're not just generating plans—you're validating that your specifications are truly parallelizable. Good decomposition produces balanced plans; poor decomposition produces 12-page monsters that signal rework needed.
Running Parallel Task Generation
Once you're confident in your plan quality, it's time to generate tasks in parallel.
Why Tasks in Parallel Matter
Tasks are the tactical specification—the actual, testable checklist of work. Running tasks in parallel matters because:
- Speed: Generate all task lists in ~20 minutes instead of 60
- Validation: Sees if feature interdependencies show up in the task lists
- Granularity: Ensures tasks are at the right size (not too big, not too small)
The Process
In each of your three terminals, run /sp.tasks:
Terminal 1 (feature-001-upload):
/sp.tasks
Terminal 2 (feature-002-grade):
/sp.tasks
Terminal 3 (feature-003-feedback):
/sp.tasks
Again, fire these off quickly. All three will run in parallel. After ~20 minutes, you'll have complete task lists for all three features.
Task Quality Indicators
When tasks are generated from good plans, they should:
- Be specific (each task has a clear acceptance criterion)
- Reference other features only at explicit integration points
- Be completable without constant cross-team communication
- Vary in complexity but cluster around a consistent size (most tasks take 1-4 hours)
If your task lists are messy (tasks that depend on "waiting for feature-002 to finish" scattered throughout feature-001), that's a sign your decomposition needs work.
Monitoring Multiple Sessions
Here's where terminal management becomes important. With three planning sessions running, you need to track:
- Which session finished first?
- Did any session error out?
- Are all three progressing at similar speed?
You can switch between terminals to check progress, but avoid constantly jumping between them.
Tip: At 10+ sessions, you'll need better tools (tmux, terminal multiplexers, or automated orchestration). For now with 3, simple tabs/windows work fine.
🤝 Practice Exercise
Ask your AI: "Analyze these 3 task lists (paste excerpts). Are tasks balanced in complexity? Do any tasks have hidden dependencies that should be explicit? Suggest improvements to task granularity."
Expected Outcome: Understanding how task list analysis reveals decomposition quality issues before implementation begins.
Try With AI
Ready to validate parallel planning quality and design for scale? Test your orchestration skills:
🔍 Explore Plan Quality & Balance:
"Analyze my 3 parallel feature plans (feature-001, feature-002, feature-003). Compare their complexity: (1) How many tasks in each? (2) What's the dependency depth? (3) Are they balanced or is one feature too ambitious? (4) Do you spot any circular dependencies or hidden integration points? Format as a comparison table showing metrics for each feature. Identify refactoring opportunities if decomposition is unbalanced."
🎯 Practice Terminal Management Strategy:
"I'm managing 3 parallel AI planning sessions right now. Help me design a terminal management strategy for 10 parallel sessions: (1) What tools would you recommend (tmux, iTerm2, VS Code terminals)? (2) How should I organize and label 10 terminals/worktrees to prevent confusion? (3) What naming conventions help track which agent works on which feature? (4) How do I monitor progress across all 10 without constant context-switching? Give me a concrete architecture."
🧪 Test Decomposition Independence:
"Evaluate whether my 3 features are truly independent enough for parallel work. My explicit dependencies: [list your dependencies, e.g., 'feature-002 needs User ID from feature-001']. Based on these dependencies: (1) What integration pain points should I expect? (2) What timing risks emerge (if feature-001 slips, does feature-002 block)? (3) Should I adjust my decomposition? (4) How do I sequence integration to minimize risk?"
🚀 Apply to Your System:
"I'm designing [describe your system with 5+ features]. Help me decompose it for parallel development: (1) Which features have zero dependencies (can start immediately)? (2) Which features have dependencies (need sequencing)? (3) What's my critical path? (4) How many agents could work in parallel? (5) Design my phased rollout strategy that maximizes parallelism while respecting dependencies."