What is CPython?
When you type python script.py into your terminal, something remarkable happens behind the scenes. Your code passes through several transformation layers before your computer actually runs it. Understanding this process—and understanding that "Python" isn't just one thing—is foundational to working effectively with the language, especially when you need to optimize multi-agent AI systems or deploy Python code in constrained environments.
In this lesson, you'll discover what CPython actually is, how it differs from other Python implementations, and how Python code becomes executable instructions. This foundation is essential for Lesson 2, where we'll explore the Global Interpreter Lock (GIL) and understand why threading behaves differently in CPython than in alternative implementations.
Section 1: What is CPython?
When you download Python from python.org and install it on your computer, you're installing CPython. This is the reference implementation of Python—the official, authoritative version of the Python language.
Let's break this down carefully. "Reference implementation" means:
-
Official Standard: CPython is the canonical definition of what "Python" means. When the Python Enhancement Proposal (PEP) process creates new features, CPython is the first to implement them. If something works in CPython, it's "officially Python."
-
Maintained by Python Software Foundation: The core Python developers (led by Guido van Rossum until 2019, now governed by a steering council) maintain CPython. It's the authoritative decision-maker for language behavior.
-
Written in C: Here's a crucial detail that will matter for everything we discuss about performance and threading—CPython isn't written in Python. It's written in C, a lower-level programming language. This design choice has profound implications for how memory is managed and how Python handles concurrent execution.
💬 AI Colearning Prompt
Before we continue, let's explore why this architecture matters:
"Why is CPython written in C instead of Python? What are the advantages of implementing Python in C? What would happen if Python was implemented entirely in Python instead?"
You'll discover that implementing a language is a bootstrapping problem—you need a lower-level language to build the higher-level one. You'll also learn about performance and integration: C allows CPython to integrate with operating systems, hardware, and performance-critical code seamlessly.
Section 2: The Python Execution Pipeline
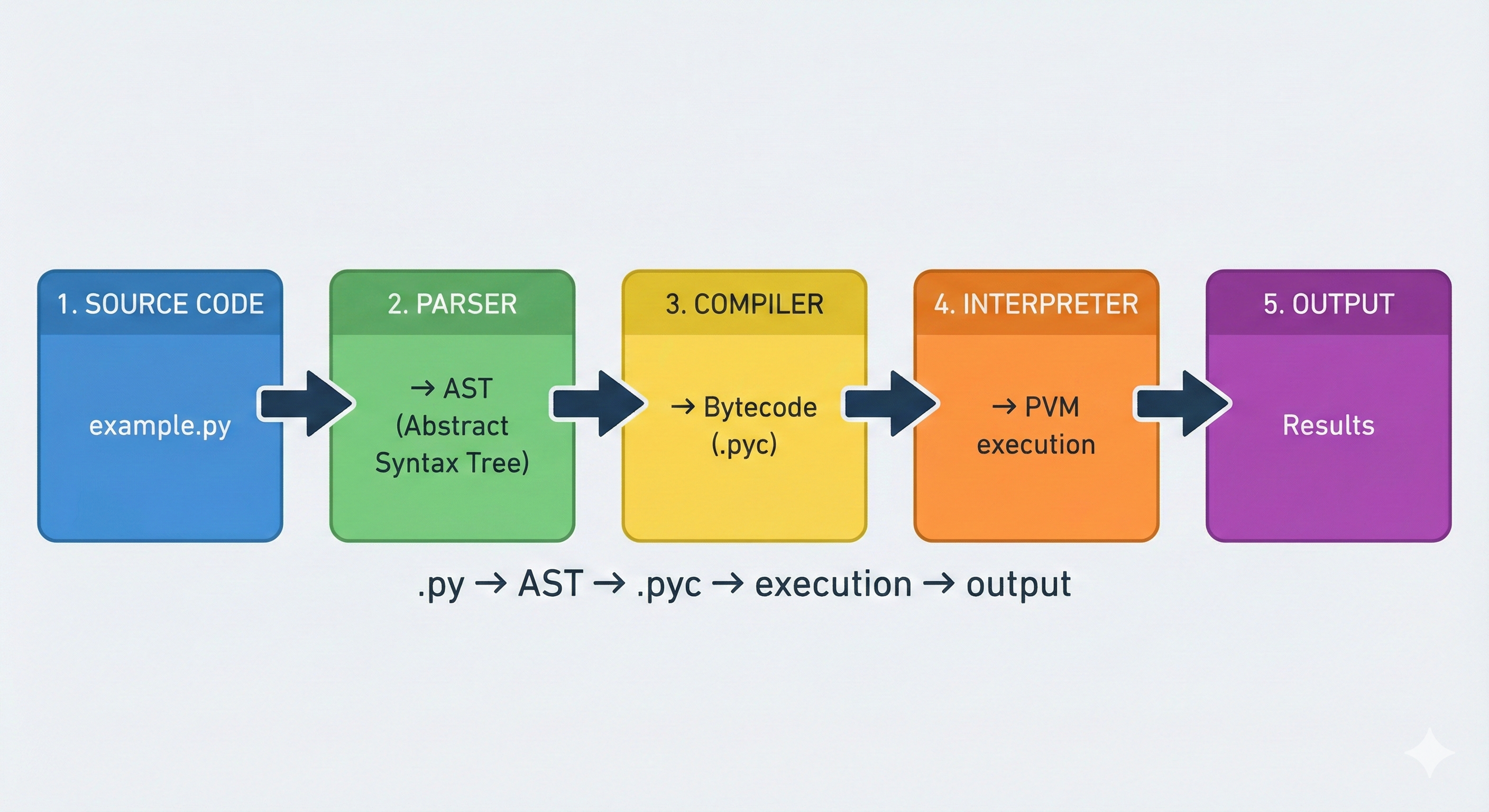
To understand CPython, you need to understand how code becomes execution. There are three main stages:
Stage 1: Source Code (Your Python Files)
You write Python code in .py files:
Loading Python environment...
This is human-readable Python. It follows Python's syntax rules and is meant for developers to understand and maintain.
Stage 2: Bytecode Compilation (The Recipe Card)
CPython doesn't execute your source code directly. Instead, it compiles your code to bytecode—a lower-level, machine-independent representation that's more efficient to execute.
Think of bytecode as a recipe card. Your source code is detailed instructions; bytecode is the essential steps condensed. When you run a Python script, CPython:
- Parses your source code
- Compiles it to bytecode
- Writes the bytecode to a
.pycfile (usually in__pycache__/) - Caches it for next time
You've probably seen those __pycache__ folders in your projects. Those contain the bytecode:
my_project/
__pycache__/
greet.cpython-314.pyc # Bytecode for greet.py
greet.py
The .cpython-314.pyc filename tells you:
cpython: This bytecode is for CPython314: This is Python 3.14.pyc: Compiled Python code
🎓 Expert Insight
In AI-native development, you don't memorize what bytecode looks like or how to read it. What matters is understanding when bytecode affects your workflow:
- Debugging: Bytecode caching means changes are sometimes compiled; understanding this prevents "why isn't my change working?" confusion
- Deployment: Bytecode is platform-independent, so you can deploy
.pycfiles instead of source (for secrecy or performance) - Performance: The compilation step happens once and is cached, making repeated runs faster
Syntax is cheap—understanding this architectural layer is gold.
Stage 3: Interpreter Execution (Following the Recipe)
The CPython interpreter reads the bytecode and executes it. The interpreter is the C program that:
- Reads bytecode instructions one by one
- Manages objects in memory
- Executes operations (add numbers, call functions, access variables)
- Returns results
Here's where it gets crucial: the CPython interpreter is single-threaded at the bytecode level. This is the Global Interpreter Lock (GIL) in action, which we'll explore in Lesson 2. For now, understand that the interpreter processes bytecode sequentially—even if you write multi-threaded code, the bytecode-level execution is single-threaded.
🚀 CoLearning Challenge
Ask your AI Companion:
"Walk me through what happens when I run
python script.py. Create a diagram showing: source code → compilation → bytecode → interpreter execution. Explain what CPython is doing at each stage, and identify where the GIL might become relevant."
Expected Outcome: You'll develop a mental model of Python execution that explains why some optimizations work better than others, and why threading behaves differently in CPython.
Section 3: Memory Management Deep Dive
CPython manages memory using two mechanisms: reference counting and garbage collection.
Reference Counting: The Primary Mechanism
Every object in CPython has a reference count—a number tracking how many parts of your code are currently using that object.
Loading Python environment...
When the reference count drops to zero, CPython immediately frees that object's memory. This is deterministic—you know exactly when memory is released.
Why is this important? Reference counting is fast and simple. It doesn't require pausing your program to scan for unused objects (which garbage collection does). For real-time systems and AI inference workloads, this predictability is valuable.
✨ Teaching Tip
Use Claude Code or Gemini CLI to explore this interactively:
"Show me Python code that demonstrates reference counting. Create objects, increase their refcount, then show what happens when refcount drops to zero. Explain what 'del' does and why it matters for memory."
Garbage Collection: Handling Cycles
Reference counting alone has a weakness: circular references. When objects refer to each other in a loop, reference counts never reach zero—even though nothing outside the cycle refers to them.
Loading Python environment...
CPython's garbage collector runs periodically to find and free these unreachable objects. It works by:
- Marking all accessible objects starting from known root references
- Sweeping unreachable objects and freeing them
The garbage collector typically runs when certain thresholds are reached (e.g., 1,000 objects created since last collection). You can control this with the gc module:
Loading Python environment...
💬 AI Colearning Prompt
"Explain the difference between reference counting and garbage collection. Why does CPython use both? What are the advantages and disadvantages of each approach?"
This exploration will help you understand why CPython's design leads to the GIL. Different designs (like PyPy's moving garbage collector) can avoid the GIL by using different memory management.
Section 4: Alternative Implementations
"Python" the language is separate from "CPython" the implementation. Several other implementations exist, each with different tradeoffs:
PyPy: Speed Through JIT Compilation
PyPy is a Python implementation written largely in Python itself. It uses Just-In-Time (JIT) compilation—analyzing code at runtime and compiling hot paths to machine code.
Source Code
↓
Interpreter (faster feedback)
↓
JIT detects "hot" code
↓
Compile to machine code
↓
Execute machine code (MUCH faster)
Tradeoff: PyPy's startup time is slower (compilation overhead), but repeated code runs much faster—sometimes 2–10x faster than CPython on compute-intensive workloads.
Use when: Your code has computational bottlenecks (matrix math, data processing, simulations). Avoid when you need immediate startup (CLI tools, serverless functions).
Jython: Python on the Java Virtual Machine
Jython runs Python code on the Java Virtual Machine (JVM), letting you:
- Use Java libraries from Python
- Deploy Python code in Java environments
- Leverage JVM optimizations and threading
Tradeoff: Jython is slower than CPython for most tasks, but gains Java ecosystem access and better native threading.
Use when: You need to integrate with Java systems or deploy in Java-only environments.
IronPython: Python on the .NET Platform
Similar to Jython but for Microsoft's .NET platform. Useful for integrating Python into Windows/C# environments.
Use when: You're in a .NET ecosystem and need Python scripting capabilities.
MicroPython: Python for Embedded Systems
MicroPython is a minimal Python implementation for microcontrollers (Arduino-like devices), IoT systems, and embedded devices.
Loading Python environment...
Tradeoff: MicroPython omits some Python features to fit in kilobytes of RAM. You get Python-like syntax for embedded systems.
Use when: Writing code for IoT devices, microcontrollers, or resource-constrained environments.
Comparison Table
| Implementation | Speed | Memory | Python Compatibility | Best For | Key Tech |
|---|---|---|---|---|---|
| CPython | Baseline | Standard | 100% | General purpose, production | Reference counting + GC |
| PyPy | 2–10x faster | More | ~95% | Compute-heavy workloads | JIT compilation |
| Jython | Slower | JVM | ~95% | Java integration | Runs on JVM |
| IronPython | Slower | CLR | ~95% | .NET integration | Runs on .NET |
| MicroPython | Fast (tiny) | Tiny | ~70% | Embedded/IoT | Minimal footprint |
Section 5: How to Detect Your Implementation
In production systems, you often need to know which Python implementation is running. The platform module provides this information:
Specification Reference: Using Python's platform module for implementation detection
AI Prompt Used: "Create a Python function using platform.python_implementation() that detects the Python implementation and returns helpful information about it."
Generated Code:
Loading Python environment...
Example Output on CPython:
implementation : CPython
version : 3.14.0
compiler : GCC 11.2.0
executable : /usr/bin/python3.14
prefix : /usr
On PyPy:
implementation : PyPy
version : 7.3.12
compiler : GCC 11.2.0
executable : /usr/bin/pypy3
prefix : /home/user/.pyenv/versions/pypy3.9-7.3.12
Validation Steps:
- Run on your local CPython installation → should print "CPython"
- If you have PyPy installed, run same script with
pypy3 script.py→ should print "PyPy" - Confirm
sys.executablepath differs between implementations - Use this in CI/CD to handle implementation-specific behavior
🚀 CoLearning Challenge
Ask your AI Companion:
"Generate a Python script that detects the implementation and conditionally enables features based on which one is running. For example: 'If PyPy, use speed optimization X. If CPython, use feature Y.' Explain the conditional logic."
Expected Outcome: You'll understand how to write implementation-aware code and recognize when different implementations require different approaches.
This is especially important in multi-agent AI systems where you might deploy on PyPy for performance but develop on CPython for compatibility.
Why This Matters in Production
Consider a data processing pipeline for AI workloads:
Loading Python environment...
This code adapts to its environment—a pattern you'll use repeatedly in production systems.
Why CPython's Design Matters for What's Coming
Understanding CPython sets up the next lesson perfectly. The key insights:
- Reference counting is CPython's primary memory strategy
- Single-threaded bytecode execution is a consequence of reference counting
- The Global Interpreter Lock (GIL) protects reference counters in threaded code
These three facts explain GIL behavior in Lesson 2, threading limitations in Lesson 3, and why async programming exists as an alternative in Lesson 4.
Alternative implementations like PyPy escape these constraints by using different memory management strategies. This is the architectural foundation for performance optimization in multi-agent AI systems—you'll choose implementations based on your workload characteristics.
Challenge 1: The CPython Internals Discovery
This is a 4-part bidirectional learning challenge where you explore CPython's architecture and design tradeoffs.
Initial Exploration
Your Challenge: Investigate CPython's execution pipeline without AI guidance.
Deliverable: Create /tmp/cpython_discovery.py containing:
- Use
platform.python_implementation()to detect your Python implementation - Use
sys.version_infoto get version details - Import
dismodule and disassemble a simple function to see bytecode - Create a simple script that:
- Calculates sum of 1 to 100
- Write both Python source and bytecode to a file
- Explain: why does CPython compile to bytecode? Why not execute source directly?
Expected Observation:
- Your Python implementation is "CPython" (likely)
- Bytecode is not human-readable but lower-level than source
- Bytecode allows CPython to interpret quickly without re-parsing
Self-Validation:
- What's the difference between compilation (source → bytecode) and execution (bytecode → behavior)?
- Why is reference counting important for memory management?
- How does bytecode differ from machine code?
Understanding Python Implementations
Your AI Prompt:
"I just discovered that Python has different implementations (CPython, PyPy, Jython, IronPython). Teach me: 1) Why are there multiple implementations instead of just one? 2) What's the difference between CPython and PyPy? 3) Why would someone use PyPy instead of CPython? 4) How do they differ in memory management and threading? Show me code that reveals these differences."
AI's Role: Explain the Python language vs CPython interpreter distinction, discuss design tradeoffs (simplicity vs speed, reference counting vs garbage collection), and preview how these choices affect threading.
Interactive Moment: Ask a clarifying question:
"You said PyPy doesn't have a GIL. But CPython does. How is that possible if they both run Python? What's the technical difference that allows one to have threading and the other not?"
Expected Outcome: AI clarifies that the GIL is a CPython implementation detail, not a Python language requirement. You understand that design choices (reference counting) cascade to threading constraints (GIL).
Exploring Design Tradeoffs
Setup: AI generates code that reveals CPython design constraints. Your job is to test it and teach AI about implementation realities.
AI's Initial Code (ask for this):
"Show me code that demonstrates: 1) Reference counting in action (creating/deleting objects shows count), 2) The overhead of reference counting vs garbage collection, 3) Why CPython needs the GIL (hint: reference counting isn't thread-safe). Use sys.getrefcount() to show actual reference counts."
Your Task:
- Run the code. Observe reference counts changing
- Create multiple objects and see memory usage
- Identify the issue: reference counting is overhead, GIL is a necessity for safety
- Teach AI:
"Your code shows that CPython counts every reference to every object. That's overhead. But you said it's necessary for safety. Why is reference counting not thread-safe? What happens if two threads try to modify the same object's reference count simultaneously?"
Your Edge Case Discovery: Ask AI:
"You mentioned PyPy uses a garbage collector instead of reference counting. What's the tradeoff? Does PyPy use less memory? More memory? Faster startup? Slower startup? When would I choose CPython vs PyPy for a real application?"
Expected Outcome: You discover that implementations are designed for different use cases—CPython optimizes for C integration and simple memory model; PyPy optimizes for execution speed. You learn to think about architectural tradeoffs.
Building a Comparison Framework
Your Capstone for This Challenge: Build an implementation-agnostic detection and profiling tool.
Specification:
- Detect Python implementation (CPython, PyPy, Jython, etc.)
- For CPython: show bytecode of a function using
dis - Measure function execution time on current implementation
- Create a report:
{implementation, version, bytecode, execution_time} - Test with different implementations if possible (or document what you'd test)
- Show reference counting (CPython only) using
sys.getrefcount() - Type hints throughout
Deliverable: Save to /tmp/implementation_profiler.py
Testing Your Work:
python /tmp/implementation_profiler.py
# Expected output:
# Implementation: CPython
# Version: 3.14.0
# Bytecode for test_function:
# 1 LOAD_CONST 0 (100)
# 2 RETURN_VALUE
# Execution time: 0.0001ms
# Reference count: 2 (for this object)
Validation Checklist:
- Code runs without errors
- Correctly identifies implementation
- Shows bytecode clearly
- Timing measurement accurate
- Reference counting works (CPython)
- Type hints complete
- Could be extended to test PyPy/other implementations
Time Estimate: 25-30 minutes (5 min discover, 8 min teach/learn, 7 min edge cases, 5 min build artifact)
Key Takeaway: CPython is one implementation among many. Its design choices (reference counting, C API, GIL) make sense given its constraints. Understanding why these choices exist prepares you for the GIL deep-dive in Lesson 2.
Try With AI
Why is CPython called an "implementation" when most developers just say "Python"?
🔍 Explore Implementation Differences:
"Compare CPython, PyPy, and Jython. Show how the same Python code (x = [1, 2, 3]) behaves differently: CPython uses reference counting, PyPy uses JIT compilation, Jython runs on JVM. What changes and what stays the same?"
🎯 Practice Bytecode Analysis:
"Write a simple function and use dis.dis() to show its bytecode. Explain how LOAD_CONST, BINARY_ADD, and RETURN_VALUE work. Why does CPython compile to bytecode before execution?"
🧪 Test Reference Counting:
"Use sys.getrefcount() to track how many references exist to an object. Create scenarios where count increases (assignment, list append) and decreases (del, scope exit). Why does CPython use this vs garbage collection?"
🚀 Apply to Performance Understanding:
"Explain why sys._is_gil_enabled() returns a boolean in Python 3.14. How does knowing your implementation (CPython with/without GIL) affect design decisions for multi-threaded programs?"