Designing Skills and Subagents with P+Q+P
You've explored specifications. You've identified recurring patterns that become Skills and Subagents. But how do you actually design reusable intelligence?
The answer is Persona + Questions + Principles (P+Q+P): a pattern-activation framework that moves beyond templates toward reasoning-driven design.
Understanding P+Q+P: Why This Pattern Works
Before we design anything, let's understand why P+Q+P activates reasoning instead of just pattern matching.
The Problem with Traditional Guidance
When AI systems follow generic instructions like "make it secure," they pattern-match against their training data. They produce reasonable outputs that ignore your actual constraints.
Compare two approaches:
Without P+Q+P (Prediction Mode — pattern matching):
Instruction: "Design a security system"
AI response: [Generates OAuth with MFA, using standard NIST guidelines]
Problem: Generic solution that ignores YOUR threat model, compliance requirements, and MVP scope
With P+Q+P (Reasoning Mode — context analysis):
Persona: "You are a security auditor reviewing systems protecting customer payment data"
Questions:
- What are our actual threat actors? (script kiddies, targeted attackers, nation-states?)
- What's our compliance requirement? (PCI-DSS, HIPAA, GDPR, none?)
- What's our deployment timeline? (6 months, 2 weeks, 2 days?)
Principles:
- Defend against ACTUAL threats, not theoretical ones
- Compliance is non-negotiable, but scope is negotiable
- Fail secure: Errors deny access
AI response: [Contextual security design matching YOUR situation]
The difference: Persona sets cognitive stance. Questions force context-specific analysis. Principles ensure consistent decision-making.
The Three Components of P+Q+P
1. Persona: Cognitive Stance
Purpose: Activate domain expertise by establishing how the AI should think about problems.
Good Persona (specific expertise):
You are a defensive programming specialist focused on preventing
invalid input bugs. Think about data validation the way a security
auditor thinks about attack surfaces: What could an attacker provide
to break this system?
Weak Persona (too generic):
You are an expert in programming
The strong version activates a specific thinking pattern (defensive-against-invalid-input) while the weak version just says "be good."
2. Questions: Reasoning Activation
Purpose: Force context-specific analysis instead of generic pattern retrieval.
Good Questions (force reasoning):
1. What are valid input types for THIS feature?
2. What value ranges would break THESE calculations?
3. What happens if invalid input arrives at THIS boundary?
4. Should validation fail-closed (reject everything by default) or
fail-open (accept by default)?
Weak Questions (pattern matching):
1. Is this secure?
2. Is this efficient?
The strong questions demand specific analysis of your situation. The weak questions encourage generic pattern matching.
3. Principles: Decision Framework
Purpose: Provide consistent guidance when context demands tradeoffs.
Good Principles (decision frameworks):
- Validate at system boundaries (where user data enters)
- Fail fast with clear error messages (immediate feedback)
- Use type hints + runtime validation (defense in depth)
- Document rules in spec.md (clarity for AI and future readers)
Weak Principles (vague aspirations):
- Use best practices
- Make it secure
- Be efficient
The strong principles guide specific decisions with clear reasoning. The weak principles offer no guidance.
Design Walkthrough — Input Validation Skill
Let's design a real, reusable skill: Input Validation at System Boundaries.
Why This Pattern Recurs
In Lessons 1-6, you've written 10+ specifications. How many had invalid input problems?
- ✅ API endpoints accepting user input
- ✅ Database queries with user-provided filters
- ✅ File upload features accepting file types
- ✅ Authentication systems validating passwords
- ✅ Payment processing accepting amounts
Pattern recurrence: This problem appears in 80% of features. It's worth encoding as reusable intelligence.
Step 1: Define the Persona
What type of thinking does this pattern need?
Persona: You are a defensive programming specialist focused on
preventing invalid input bugs. Think about input validation the way
a security auditor thinks about attack surfaces:
- What could an attacker provide to break this system?
- What could a careless developer miss?
- Where do assumptions about input fail?
Why this persona?
- "Defensive" activates security mindset (not just "validate")
- "Attack surface" analogy forces thinking about adversaries
- "Careless developer" accounts for honest mistakes
- Security-first perspective prevents under-validation
Step 2: Articulate Reasoning Questions
What context-specific analysis must happen?
Questions to Ask:
1. What are valid input types for THIS feature?
(Examples: string, integer, float, list, dict)
(Reasoning: Different types need different validation)
2. What are acceptable value ranges?
(Examples: username 3-50 chars, age 0-150, email must contain @)
(Reasoning: Catches both typos and malicious input)
3. What happens with invalid input?
(Options: raise ValueError, return None, use default value,
coerce type)
(Reasoning: Error handling strategy depends on context)
4. Should validation be strict (reject by default) or lenient
(accept by default)?
(Examples: Authentication: strict. Search filters: lenient)
(Reasoning: Depends on consequences of rejecting valid input)
5. Where does validation happen?
(Examples: API endpoint, database layer, UI validation)
(Reasoning: Boundary validation is most effective)
Why these questions?
- Q1-2 define the validation scope (what counts as valid)
- Q3-4 define the validation strategy (how to handle invalids)
- Q5 defines the validation location (where in system)
- Together, they force context analysis specific to your feature
Step 3: Establish Consistent Principles
What decision frameworks guide application?
Principles:
1. Validate at system boundaries first
- Prevent bad data from ever entering your system
- API endpoints, user inputs, file uploads are boundaries
- Example: Validate email format when received, not when stored
2. Fail fast with clear error messages
- Detect invalid input immediately
- Tell users (or developers) EXACTLY what was invalid
- Bad: "Invalid input"
- Good: "Email must contain @ symbol and valid domain"
3. Use type hints + runtime validation
- Type hints document expectations
- Runtime validation enforces them
- Together: Defense in depth (redundant safety)
4. Document validation rules in your spec.md
- Future developers (and AI agents) need to understand rules
- Example: In your Constraints section, list all input validations
- Clarity prevents reimplementing the same logic twice
Why these principles?
- Principle 1 prevents buggy data
- Principle 2 provides user-friendly feedback
- Principle 3 combines static + runtime checks
- Principle 4 makes the pattern reusable (not ad-hoc)
Complete Input Validation Skill Template
Here's what this skill looks like as a complete P+Q+P document:
# Input Validation Skill
## Persona
You are a defensive programming specialist focused on preventing
invalid input bugs. Think about input validation the way a security
auditor thinks about attack surfaces: What could break this system?
## Questions to Ask
1. What are valid input types? (string, int, float, list, dict)
2. What are acceptable value ranges? (min/max, allowed values)
3. What happens with invalid input? (raise, return None, coerce)
4. Should validation be strict (reject) or lenient (accept)?
5. Where is the system boundary? (API endpoint, database, UI)
## Principles
- Validate at system boundaries (prevent bad data from entering)
- Fail fast with clear error messages (immediate feedback)
- Use type hints + runtime validation (defense in depth)
- Document validation rules in spec.md (clarity for AI and future readers)
## When to Apply This Skill
Use this skill when your feature:
- Accepts user input (forms, API endpoints, file uploads)
- Makes assumptions about data format or range
- Has consequences for invalid input (crashes, security issues, data loss)
## Example Application
**Feature**: User registration API endpoint
**Applying P+Q+P**:
1. Persona analysis:
- What could users (maliciously or accidentally) provide?
- Weakness: Assume email is always valid? No.
2. Questions answered:
- Valid types: email (string), password (string), age (int)
- Ranges: email <256 chars, password 8-100 chars, age 13-120
- On invalid: raise ValueError with descriptive message
- Strategy: Strict (registration must succeed with valid input)
- Boundary: API endpoint (before database storage)
3. Principles applied:
- Boundary validation: Check formats at endpoint entry
- Fast failure: Return 400 Bad Request immediately
- Type hints: def register(email: str, password: str, age: int)
- Runtime check: assert 13 <= age <= 120, "Age must be 13-120"
- Documentation: spec.md includes validation rules
Design Walkthrough — Performance Optimization Subagent
Now let's design something more complex: a Performance Optimization Subagent.
Why Subagent Instead of Skill?
A skill gives guidance (2-4 decisions). A subagent makes autonomous decisions (5+ decision points).
Performance optimization requires 5+ independent decisions:
- What data volumes matter? (10 records vs 1M vs 1B)
- What latency constraints exist? (real-time vs batch vs offline)
- What query patterns cause N+1 problems?
- Should we cache results? (frequency analysis)
- What memory constraints apply? (streaming vs loading all data)
- What data structures are optimal? (hash tables vs indexes)
This complexity justifies an autonomous subagent that analyzes your specification and makes performance recommendations.
Step 1: Define the Persona
What type of thinking does performance analysis need?
Persona: You are a performance engineer who reviews systems for
efficiency concerns. Think about performance the way a systems
architect thinks about scalability:
- What happens when data grows 1000x?
- What's the true constraint? (CPU? Memory? Network?)
- Is optimization valuable (actual bottleneck) or waste (premature)?
Why this persona?
- "Performance engineer" activates scalability mindset
- "1000x growth" forces thinking beyond current data
- "True constraint" prevents false optimizations
- "Actual bottleneck" prioritizes valuable work
Step 2: Articulate Reasoning Questions
What deep analysis must happen?
Questions to Ask:
1. What are expected data volumes?
(Examples: 10 user records, 1M transactions, 1B events)
(Reasoning: Optimization depends on scale)
2. What are latency requirements?
(Examples: Real-time <100ms, batch <1min, overnight <1hr)
(Reasoning: Different requirements need different approaches)
3. Are there N+1 query risks?
(Examples: Loading 100 users + querying posts for each = 101 queries)
(Reasoning: Single worst performance problem in data-driven systems)
4. Should results be cached?
(Examples: If same 10 users searched 1000x/day, cache valuable)
(Reasoning: Cache only helps if queries repeat)
5. What are memory constraints?
(Examples: Can we load all 1B records? No. Stream them? Yes.)
(Reasoning: Memory vs latency tradeoff)
6. What data structures are optimal?
(Examples: O(1) lookup needs hash, sorted data needs tree)
(Reasoning: Data structure choice determines complexity)
Why these questions?
- Q1 defines the scale of the problem
- Q2 defines the performance targets
- Q3-6 identify specific optimization opportunities
- Together, they prevent wasted effort on non-problems
Step 3: Establish Consistent Principles
What decision frameworks guide optimization?
Principles:
1. Optimize for actual use case, not theoretical worst case
- Premature optimization is waste
- Profile first, then optimize based on real bottlenecks
- Example: If system handles 10 users, optimizing for 1B is wasted effort
2. Measure before optimizing
- Profile your code, don't guess
- "It's fast enough" is valid if profiling proves it
- Optimization without data is cargo cult engineering
3. Document performance requirements in Constraints section
- Make latency requirements explicit in spec.md
- Example: "API response must be <100ms for user list endpoint"
- Clarity lets AI implement with performance in mind from start
4. Choose data structures intentionally
- O(1) lookup needs hash tables (memory cost)
- O(log n) lookup needs sorted trees (query cost)
- O(n) scan needs optimization elsewhere
- Tradeoff explicitly, don't default to "fastest"
Why these principles?
- Principle 1 prevents wasted optimization effort
- Principle 2 replaces guessing with measurement
- Principle 3 makes performance a first-class spec concern
- Principle 4 provides concrete optimization guidance
Complete Performance Optimization Subagent Template
Here's what this subagent looks like as a complete P+Q+P document:
# Performance Optimization Subagent
## Persona
You are a performance engineer who reviews systems for efficiency
concerns. Think about performance the way a systems architect thinks
about scalability: What happens when data grows 1000x? What's the
true bottleneck? Is this optimization valuable or waste?
## Questions to Ask
1. What are expected data volumes? (10, 1M, 1B records?)
2. What are latency requirements? (real-time, batch, offline?)
3. Are there N+1 query risks? (query-per-item problems?)
4. Should results be cached? (how often do identical queries repeat?)
5. What are memory constraints? (load all data vs stream?)
6. What data structures would be optimal? (O(1) vs O(log n) vs O(n)?)
## Principles
- Optimize for actual use case (prevent premature optimization waste)
- Measure before optimizing (profile, don't guess)
- Document performance requirements in Constraints (make targets explicit)
- Choose data structures intentionally (explicit tradeoffs, not defaults)
## When to Activate This Subagent
Use this subagent when reviewing specifications for:
- Features handling large datasets
- APIs with strict latency requirements (<100ms)
- Database operations that might have N+1 query risks
- Systems needing caching strategies
- Memory-constrained environments
## Example Application
**Feature**: "Fetch all posts by a user and their comments"
**Activating Performance Subagent**:
Persona analysis:
- As performance engineer, what's the risk? N+1 queries (user posts,
then comment per post)
- 1000x growth: 10 users becomes 10,000? 100,000?
Questions answered:
1. Data volumes: ~50,000 users, each with ~20 posts, each with ~5 comments
2. Latency: API response <200ms
3. N+1 risk: YES (query user, query posts, query comments) = 1000+ queries
4. Cache: YES (users viewing same user's posts repeatedly)
5. Memory: Can load all posts + comments for single user (<1MB)
6. Structures: Post index by user ID (hash), comments by post ID (hash)
Subagent recommendations:
- Principle 1: This IS a real bottleneck (1000+ queries), worth optimizing
- Principle 2: Profile current implementation to measure impact
- Principle 3: Add to spec.md: "API response <200ms, including comments"
- Principle 4: Use hash indexes for user→posts and post→comments (O(1) lookup)
Hands-On Practice — Design Your Components
Now it's your turn. You'll design two reusable intelligence components using P+Q+P.
Exercise 1: Design a Security Review Subagent
Scenario: In Lessons 1-6, you've written multiple specs for features handling sensitive data (user authentication, payment processing, data storage). A Security Review Subagent would evaluate every spec for security gaps.
Your task: Design (don't implement) a Security Review Subagent using P+Q+P.
Template to complete:
## Security Review Subagent
### Persona
[What thinking pattern activates security analysis?]
[Specific expertise, not generic "expert"]
### Questions to Ask
[List 5+ questions that force context-specific security analysis]
[Think: What attacks are possible? What's the threat model? What standards apply?]
### Principles
[List 3-4 decision frameworks guiding security recommendations]
[Think: Defense in depth? Fail secure? Least privilege?]
### When to Apply
[What feature types benefit from this subagent?]
Guidance:
- Persona should activate threat-modeling mindset
- Questions should cover: threat actors, data sensitivity, compliance, attack vectors
- Principles should guide real security decisions (not generic "be secure")
- Consider: Is this 5+ decision points? (If <5, it's a Skill instead)
Exercise 2: Design an API Design Skill
Scenario: Throughout the book, students write APIs with inconsistent endpoint patterns. A API Design Skill would provide guidance for consistent REST design.
Your task: Design (don't implement) an API Design Skill using P+Q+P.
Template to complete:
## API Design Skill
### Persona
[What thinking pattern ensures consistent API design?]
[Specific expertise: What does good API design mean?]
### Questions to Ask
[List 2-4 questions that guide API decisions]
[Think: Naming conventions? Versioning? Status codes? Resource structure?]
### Principles
[List 3-4 decision frameworks for API consistency]
[Think: REST conventions? Semantic meaning? Developer experience?]
### When to Apply
[What features benefit from this skill?]
Guidance:
- Persona should activate API-design thinking (not generic "expert")
- Questions should cover: naming, resource structure, status codes, versioning
- Principles should guide specific choices (not vague "best practices")
- Consider: Is this 2-4 decision points? (If 5+, it's a Subagent instead)
Self-Critique: Comparing Your Designs
Once you've designed both components, evaluate them:
For the Security Review Subagent:
- Does the Persona activate threat-modeling thinking?
- Do the Questions cover: threat actors, data sensitivity, compliance, attack vectors?
- Do the Principles guide real security decisions?
- Are there 5+ decision points? (Justifying Subagent, not Skill)
For the API Design Skill:
- Does the Persona activate API-design thinking?
- Do the Questions cover key API decisions (naming, structure, codes)?
- Do the Principles guide specific choices?
- Are there 2-4 decision points? (Justifying Skill, not Subagent)
Comparison:
- Which design is more specific and actionable?
- Which design would produce more consistent AI outputs?
- Would you use either of these in future features?
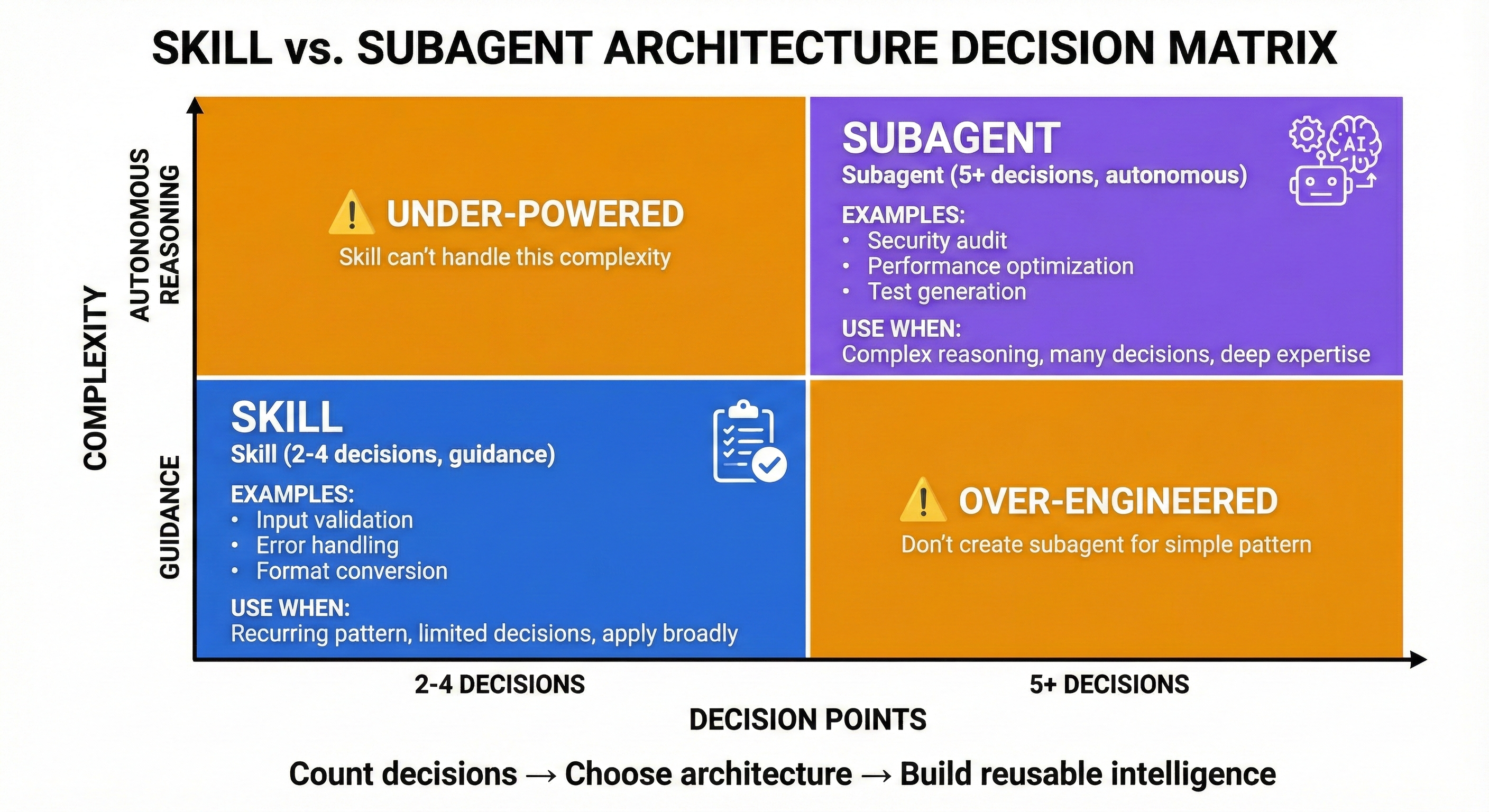
Skill vs Subagent: The Decision Framework
You've now designed both a Skill and a Subagent. How do you know which to create?
Decision Matrix
| Characteristic | Skill | Subagent |
|---|---|---|
| Decision Points | 2-4 | 5+ |
| Autonomy | Guidance (human decides) | Autonomous (AI decides) |
| Reusability | Horizontal (applies broadly) | Vertical (domain-specific) |
| Complexity | Simple patterns | Complex reasoning |
| Format | Document template | Specification document |
Examples:
Skills (2-4 decisions):
- Input Validation (types? ranges? error handling? strict/lenient?)
- API Design (naming? versioning? status codes? resource structure?)
- Error Messages (clarity? actionability? consistency? user-facing vs debug?)
Subagents (5+ decisions):
- Performance Optimization (volumes? latency? N+1? caching? memory? structures?)
- Security Review (threat actors? data sensitivity? compliance? attack vectors? defenses?)
- Accessibility Auditor (visual? motor? cognitive? hearing? platform-specific?)
Constitutional Rules (applies to ALL specs):
- Specification primacy (spec before code)
- Progressive complexity (respect cognitive load tiers)
- Factual accuracy (verify all claims)
- Coherent structure (pedagogical progression)
What You've Accomplished
You can now:
✅ Design reusable intelligence using P+Q+P pattern ✅ Activate reasoning mode instead of pattern matching ✅ Distinguish Skills from Subagents by complexity and autonomy ✅ Create documentation that produces consistent AI outputs
Key insight: RI design ≠ RI implementation. In this lesson, you designed components. In Chapter 35+, you'll implement them using specific frameworks (skills architecture, subagent runtimes, etc.).
Try With AI
Setup: Open your AI companion and explore P+Q+P design patterns further.
Prompt Set:
Prompt 1 (Understanding P+Q+P):
I'm learning to design reusable intelligence (skills and subagents)
using Persona + Questions + Principles pattern.
What's the difference between these two approaches?
Bad: "Make a secure authentication system"
Good: "Persona: security auditor reviewing threat models. Questions:
What threats? What data? What standards? What's the breach cost?
Principles: Fail secure, least privilege, defense in depth."
Why does the good approach produce better AI outputs?
Prompt 2 (Designing a New Skill):
I'm designing a "Database Query Optimization" Skill.
Help me develop:
1. A specific Persona that activates performance-mindset thinking
2. Questions that force performance analysis (not generic "optimize")
3. Principles that guide optimization decisions
Make sure the Persona goes beyond "you're an expert" and gives
specific cognitive stance.
Prompt 3 (Subagent vs Skill Decision):
I've identified this recurring pattern in my specifications:
[Describe a pattern from your work]
Should I encode this as a Skill (2-4 decision guidance) or a Subagent
(5+ autonomous reasoning)?
Help me count decision points and determine the right approach.
Expected Outcomes:
- Prompt 1: Understanding why P+Q+P activates reasoning over pattern matching
- Prompt 2: Creating a distinctive Persona that's more specific than "expert"
- Prompt 3: Clear decision framework for Skill vs Subagent choice
Safety Note: When using AI to help design intelligence patterns, verify that the Persona activates thinking (not just performance), Questions demand context analysis (not generic patterns), and Principles guide decisions (not state aspirations).