Anatomy of a Specification
In Lesson 1, you learned that vague specifications cost time, money, and sanity. Your AI companion built something technically correct but wrong for your actual needs.
Here's the key insight: Clarity prevents miscommunication.
In this lesson, you'll learn to structure that clarity. You'll discover what a professional specification looks like, why success criteria belong FIRST (not last), and how to write your own spec.md file by hand.
This is manual foundation work — building your understanding before AI collaboration. No AI agents. Just you, a blank document, and the structure that turns vague ideas into executable plans.
What Makes a Specification
A specification (or spec) is a structured, behavior-oriented document that clearly describes what a feature should do, under what constraints, and how you'll know it's correct.
Not just any document — a real spec:
- ✅ Has clear intent — "What problem does this solve?"
- ✅ Defines constraints — "What must ALWAYS be true?"
- ✅ Includes acceptance criteria — "How do we verify it works?"
- ✅ Is testable — "Can we write automated tests from this?"
- ✅ Survives iteration — "Can we reference this 6 months from now?"
What it's NOT:
- ❌ A brainstorm document (too vague)
- ❌ A detailed prompt to an AI (one-time use, not reusable)
- ❌ Source code (belongs in the codebase, not the spec)
What Is Specification-Driven Development?
Specification-Driven Development (SDD) is a software development workflow where you write specifications BEFORE code, treating specs as the primary source of truth.
The SDD Workflow:
- Write spec first → Define intent, constraints, success criteria
- Generate/write code → Implementation from spec
- Validate → Verify code matches spec acceptance criteria
- Iterate → Refine spec if requirements change, regenerate code
Key Principle: Code is the OUTPUT of specification, not the INPUT. The spec comes first, always.
How SDD Differs from Other Approaches:
| Approach | Workflow | Problem |
|---|---|---|
| Vibe coding | Prompt → hope | No structured spec, AI guesses intent |
| Code-first | Code → documentation | Spec written after code exists (reactive) |
| Traditional TDD | Tests → code | Tests guide code, but no overarching spec |
| SDD | Spec → tests + code | Specification guides both implementation AND validation |
In SDD, the specification is the authoritative document that drives both your tests and your implementation.
The Evals-First Principle
Here's the core insight that makes SDD work: You define success criteria BEFORE you implement.
This is called the evals-first principle.
Why Evals-First?
When you write acceptance criteria first, you create a contract between yourself and the implementation:
- Clarity: You force yourself to think about success, not just the happy path
- Validation: You have a concrete checklist to verify the implementation works
- Debugging: When something fails, you know exactly what it was supposed to do
- Handoff: Other team members (or AI agents) can verify correctness independently
Evals Come BEFORE Code
Wrong approach (implementation-first):
1. Write code
2. Test it
3. Hope it matches intent
4. (Optional) Write success criteria retrospectively
Right approach (evals-first):
1. Define success criteria (acceptance tests)
2. Specify constraints and edge cases
3. Generate/write code
4. Verify against success criteria
Example: Configuration File Manager
WITHOUT evals-first (vague):
Add a feature to save and load app settings
WITH evals-first (specific):
Acceptance Criteria:
- Function saves Python dict to JSON file without errors
- Function loads JSON file and returns dict with correct keys/values
- Function creates file if it doesn't exist (with default settings)
- Function handles missing files gracefully (raises FileNotFoundError)
- Function validates JSON format before loading (catches JSONDecodeError)
When you write these criteria first, you're writing your acceptance tests. The implementation must satisfy all of them. This is evals-first.
🎓 Expert Insight
In production software, "we'll figure out success later" is how projects slip schedules. Evals-first forces clarity upfront. It's harder initially but saves massive rework later.
Anatomy of a Specification
A production-ready spec.md file has these sections:
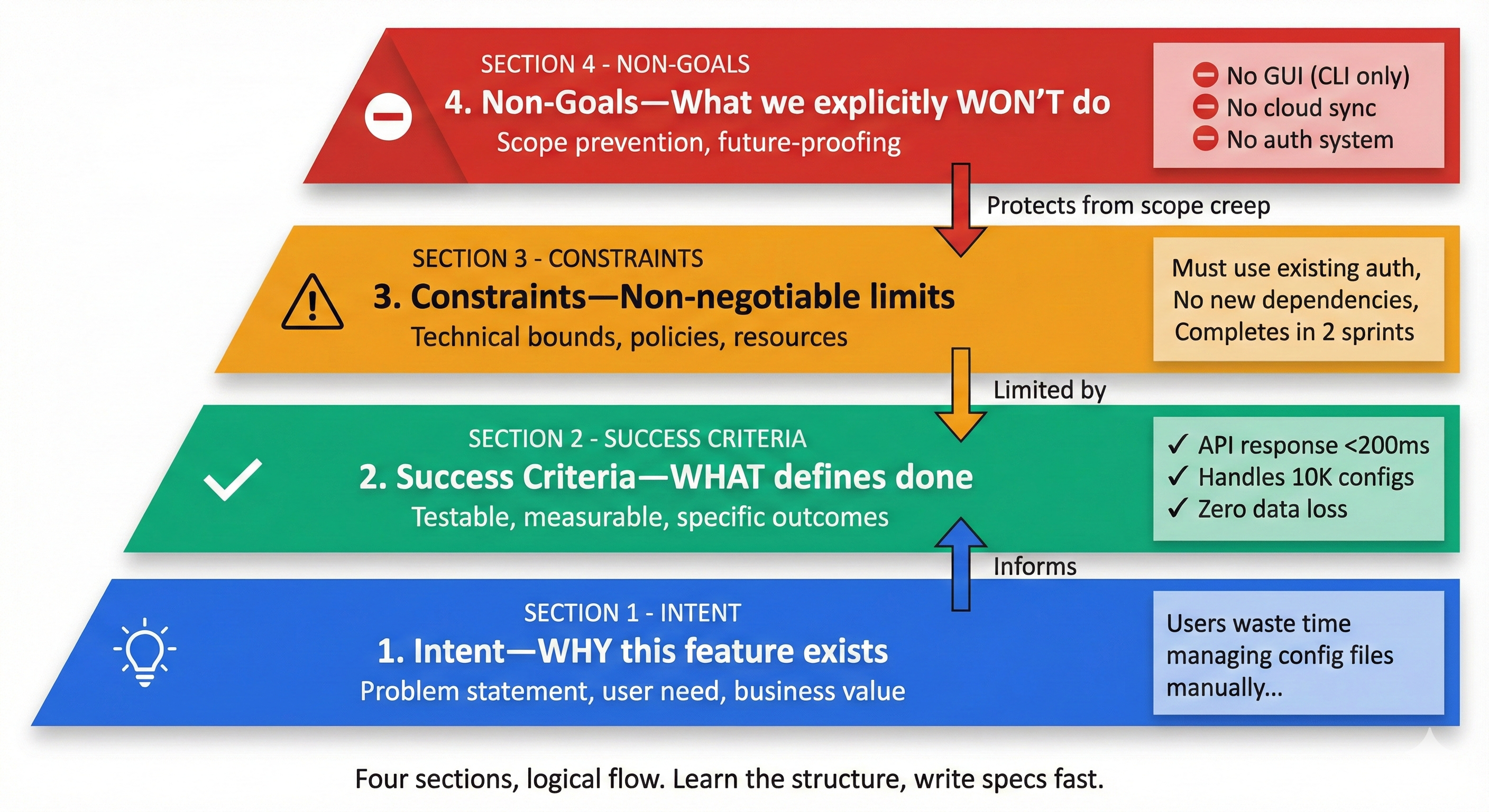
1. Intent (What problem does this solve?)
One sentence capturing the purpose.
Why is this feature worth building? What user need does it address?
Example:
"Applications need to persist user preferences (theme, font size, log level) across sessions without requiring environment variables or command-line arguments."
2. Success Criteria (How do we know it works?)
Bulleted list of verifiable outcomes.
Each criterion should be testable, not vague.
Example:
- save_config(settings: dict) saves dict to config.json without errors
- load_config() returns dict with all keys from previous save
- load_config() returns default_settings if config.json doesn't exist
- load_config() raises JSONDecodeError if config.json is corrupted
- Settings persist across multiple program runs
3. Constraints (What must always be true?)
Non-negotiable requirements that limit implementation choices.
These can include technology choices when justified.
Example:
- Must use only built-in Python json module (no external libraries)
- Config file must be valid JSON (parseable without errors)
- Must handle file permission errors gracefully (e.g., read-only files)
- Must not allow null values in configuration settings
When to include tech stack in constraints:
- ✅ DO specify when technology choice matters: "Must use Python's json module (deployment environment restrictions)"
- ✅ DO specify when team expertise limits options: "Must use PostgreSQL (team familiar with SQL)"
- ❌ DON'T over-specify when intent is general: Don't say "Use React with Redux" when "Build interactive web UI" is sufficient
Good constraint: Balances intent (general problem) with justified technical boundaries (specific tooling when required).
4. Non-Goals (What's intentionally NOT included?)
Features explicitly deferred or out of scope.
Prevents scope creep during implementation.
Example:
- Encryption of config file (plain JSON for MVP)
- Configuration versioning/migration logic (v2)
- GUI config editor (command-line only)
- Cloud sync across devices (v2)
Example: Configuration File Manager Specification
Here's a real specification for a configuration file manager, with explanations of each section:
# Specification: Configuration File Manager
## Intent
Python applications need a way to save and load user settings (log level, output format, timeout values) across program runs without hardcoding values or requiring command-line arguments every time. This feature allows applications to persist configuration to a JSON file and restore it on startup.
**Why this matters**: Settings persistence improves user experience (no reconfiguration every run) and enables production-ready applications (production apps store config separately from code).
---
## Success Criteria (Acceptance Tests)
- save_config(settings: dict, filename: str) writes settings dict to JSON file without errors
- load_config(filename: str) returns dict with all keys/values from saved file
- load_config(filename: str) returns default settings dict if file doesn't exist
- load_config(filename: str) raises FileNotFoundError if filename is invalid
- Settings persist correctly across multiple program runs (verify by running program twice)
- Function handles UTF-8 encoded text correctly
**Why these criteria?**: Each criterion is testable and measurable. We can write automated tests that verify file operations, error handling, and data integrity.
---
## Constraints
- Must use only Python's built-in json module (no external libraries like pyyaml)
- Config file must be valid JSON (parseable by json.loads without errors)
- Must handle file permission errors gracefully (read-only files on Unix systems)
- Default settings must include all required keys (no partial configs)
- Must work with both relative paths (config.json) and absolute paths (/home/user/.myapp/config.json)
**Why constraints?**: These limit implementation choices and ensure robustness. "Built-in only" prevents dependency bloat; "handle permissions" ensures Unix/Linux compatibility; "absolute and relative paths" ensures flexibility.
---
## Non-Goals (Intentionally Deferred)
- Encryption of config file (plain JSON for MVP, v2 if needed)
- Configuration versioning/migration (v2 when schema changes)
- GUI config editor (command-line only)
- Cloud sync across devices (v2)
**Why non-goals?**: Prevents scope creep. MVP version keeps it simple (plain JSON); encryption/versioning/sync add complexity that can wait.
---
## Implementation Considerations
- Default settings location: `config.json` in current working directory (or configurable path)
- File encoding: UTF-8 (supports non-ASCII characters)
- Error handling: Catch FileNotFoundError (file doesn't exist), JSONDecodeError (invalid JSON)
- Return type: dict (Python native data structure)
- Function signatures:
```python
def save_config(settings: dict, filename: str = "config.json") -> None:
"""Save settings dict to JSON file."""
def load_config(filename: str = "config.json", defaults: dict = None) -> dict:
"""Load settings from JSON file, return defaults if file missing."""
Test Scenarios
| Scenario | Steps | Expected Result |
|---|---|---|
| Save new config | Call save_config({"log_level": "DEBUG"}) | config.json created with JSON content |
| Load existing config | Call load_config() after save | Returns {"log_level": "DEBUG"} |
| Load missing file | Call load_config("missing.json") | Returns default_settings dict |
| Load corrupted JSON | File contains invalid JSON; call load_config() | Raises JSONDecodeError with message |
| Load with absolute path | Call load_config("/tmp/app_config.json") | Correctly reads from absolute path |
| Permission denied (Unix) | Config file has read-only permissions; call load_config() | Raises PermissionError |
What This Specification Contains
Section 1 (Intent): Answers "why are we building this?"
- ✅ Specific problem (settings need to persist across runs)
- ✅ Production context (production apps store config separately from code)
Section 2 (Success Criteria): These become your acceptance tests
- ✅ Each criterion is testable (can write automated tests for file I/O, error handling, persistence)
- ✅ You can write automated tests that verify these
- ✅ No ambiguity ("returns dict with all keys/values" is measurable, not "works correctly")
Section 3 (Constraints): These guide implementation decisions
- ✅ "Built-in json module only" limits technology choices (prevents external dependency bloat)
- ✅ "Handle file permissions" ensures cross-platform robustness
- ✅ "Support relative and absolute paths" enables flexibility
Section 4 (Non-Goals): This prevents scope creep
- ✅ "Encryption in v2" defers complexity to later release
- ✅ "CLI only (no GUI)" keeps MVP scope focused
Implementation notes: Technical context for whoever builds this
Test scenarios: Concrete examples of how success criteria play out
Quality Awareness — Good Specs vs Bad Specs
You've seen what a good specification looks like. But how do you recognize a bad spec—and more importantly, how do you fix it?
Quality isn't about length or formality. It's about clarity, testability, and completeness.
Good Spec vs Bad Spec Comparison
❌ Bad Spec (Vague Intent):
Make the system fast
Problem: "Fast" is subjective. Fast for what? How fast? Measured how?
✅ Good Spec (Clear Intent):
API response time must be <200ms for 95th percentile of requests under normal load (1000 req/sec)
Why better: Measurable (200ms), specific percentile (95th), defined load (1000 req/sec).
❌ Bad Spec (Untestable Success Criteria):
UI should look good and be user-friendly
Problem: "Look good" and "user-friendly" are opinions, not testable criteria.
✅ Good Spec (Testable Success Criteria):
- All buttons have 8px padding and use primary color #007bff
- Font size is 16px minimum for body text (WCAG AA compliance)
- All interactive elements have 44x44px touch targets (mobile accessibility)
Why better: Concrete measurements (8px, 16px, 44x44px), verifiable (color code, WCAG standard).
❌ Bad Spec (Missing Constraints):
Save user data to file
Problem: What format? What encoding? What happens if file exists? If disk is full?
✅ Good Spec (Explicit Constraints):
- File format: JSON (UTF-8 encoding)
- If file exists: Overwrite with new data
- If disk full: Raise OSError with clear message
- File path: Relative paths resolved from current working directory
Why better: No ambiguity. Every edge case addressed.
❌ Bad Spec (Over-Specification):
Use PostgreSQL 14.2 with connection pooling (pgbouncer) on port 5432,
with max_connections=200, shared_buffers=256MB, effective_cache_size=1GB
Problem: Over-constrains implementation. What if PostgreSQL 15 is better? What if pooling isn't needed?
✅ Good Spec (Balanced Constraints):
- Database: PostgreSQL 14+ (team expertise, production environment)
- Connection management: Must support concurrent connections (implementation flexible)
Why better: Specifies intent (concurrent connections) with justified technology choice (PostgreSQL 14+), without micromanaging configuration.
Quality Checklist for Specifications
Before finalizing any spec, validate against these criteria:
1. Clear Intent?
- ✅ Answers "What problem does this solve?"
- ✅ Explains why this feature matters (user value, business need)
- ❌ Avoid: Vague statements like "improve user experience" without specifics
Self-Check: Can someone unfamiliar with the project understand the purpose in 30 seconds?
2. Testable Success Criteria?
- ✅ Each criterion is measurable (numbers, formats, behaviors)
- ✅ Can write automated tests from these criteria
- ❌ Avoid: Subjective terms like "works well", "looks nice", "is fast"
Self-Check: Could I write a pytest test that verifies this criterion passes or fails?
3. Explicit Constraints?
- ✅ Technology choices are justified (team expertise, environment limits)
- ✅ Edge cases are handled (errors, missing data, invalid inputs)
- ✅ Non-negotiables are stated clearly
- ❌ Avoid: Assuming "obvious" behavior (always make it explicit)
Self-Check: Are there any "what if...?" questions left unanswered?
4. Prevents Scope Creep?
- ✅ Non-goals section explicitly defers features
- ✅ MVP scope is clear
- ❌ Avoid: Feature lists without priorities
Self-Check: If someone asks "What about [feature X]?", can I point to Non-Goals and say "v2"?
5. No Ambiguity?
- ✅ Technical terms are defined or industry-standard
- ✅ Examples illustrate expected behavior
- ❌ Avoid: Terms like "handle properly", "as needed", "reasonable"
Self-Check: Could two developers implement this independently and produce identical behavior?
Common Specification Pitfalls
Pitfall 1: Vague Language
❌ "System should handle errors gracefully" ✅ "System catches FileNotFoundError and returns default_settings dict"
Pitfall 2: Missing Edge Cases
❌ "Function divides two numbers" ✅ "Function divides two numbers; raises ZeroDivisionError if divisor is 0"
Pitfall 3: Over-Specification (Premature Optimization)
❌ "Use quicksort algorithm for sorting (O(n log n) average case)" ✅ "Sort user list by name (alphabetical order)"
Why: Intent is "sort by name". Algorithm choice (quicksort vs mergesort vs Python's Timsort) is implementation detail.
Pitfall 4: Conflating Spec with Implementation
❌ "Use for loop to iterate through config keys and write each to file" ✅ "Save config dict to JSON file"
Why: Spec defines what (save to JSON), not how (loop implementation).
Pitfall 5: Forgetting Why
❌ "Password reset tokens expire after 30 minutes" ✅ "Password reset tokens expire after 30 minutes (security: prevents token reuse if email compromised)"
Why: Rationale helps future developers understand tradeoffs.
Quality Integration Example: CSV Exporter
Let's apply quality thinking to the CSV exporter from the practice exercise:
❌ Vague Version:
Export data to CSV file
✅ Quality Version:
## Intent
Applications need to export Python list-of-dicts to CSV format for
non-technical users to open in Excel/Google Sheets.
## Success Criteria
- export_to_csv(data: list[dict], filename: str) writes valid CSV file
- CSV opens in Excel without errors
- Column headers match dict keys from first row
- Special characters (commas, quotes) are escaped per RFC 4180
- Empty data list produces valid CSV with headers only
## Constraints
- Must use Python's built-in csv module (no pandas—too heavy)
- File encoding: UTF-8 (international character support)
- Must handle empty lists gracefully (no crashes)
## Non-Goals
- Custom delimiters (comma-only for MVP)
- Excel .xlsx format (CSV only)
- Data validation (caller's responsibility)
Quality improvements made:
- Intent explains why (for non-technical users)
- Success criteria are testable (can verify CSV opens in Excel)
- Constraints are justified (no pandas—too heavy)
- Edge cases addressed (empty lists, special characters)
- Non-goals prevent scope creep (no xlsx, no validation)
Memory Banks vs Specs: Understanding the Distinction
Before diving deeper into specs, it's crucial to understand an important distinction: specs are not the same as memory banks.
Memory Banks (Constitutions / Steering)
Memory banks are persistent knowledge that applies across ALL AI coding sessions in your codebase:
- Rules files and coding standards
- High-level product vision and descriptions
- Architecture patterns and principles
- Technology stack decisions
- Security and compliance requirements
Think of memory banks as permanent organizational knowledge - the foundation that every feature must respect.
Examples:
- "All passwords must use bcrypt with cost factor 12+"
- "All API endpoints require authentication via JWT"
- "Test coverage must exceed 80%"
- "We use FastAPI for backends, React for frontends"
Specs (Specifications)
Specs are ephemeral or semi-permanent artifacts tied to specific features or changes:
- Functional requirements for a particular feature
- Acceptance criteria for a user story
- Test scenarios for specific functionality
- Implementation details for one component
Think of specs as temporary blueprints - relevant only to the tasks that create or change that particular functionality.
Examples:
- "Password reset system: 30-minute token expiry, rate limiting, email-only recovery"
- "User profile page: display name, avatar, bio, edit functionality"
- "Payment checkout: support credit cards via Stripe, handle declined cards"
The Key Difference
| Aspect | Memory Bank | Spec |
|---|---|---|
| Scope | Entire codebase | Specific feature/change |
| Lifetime | Permanent (or long-lived) | Temporary or feature-lifetime |
| Applies to | ALL development work | Only this feature's tasks |
| Changes | Rarely (represents stable principles) | Frequently (as feature evolves) |
| Example | "Use bcrypt always" | "Password reset: 30-min expiry" |
Why this matters: When an AI agent works on your code, it should:
- Always reference the memory bank (permanent rules)
- Only reference the relevant spec (feature-specific details)
This distinction prevents confusion and ensures AI agents apply the right level of context to their work.
🎓 Expert Insight
In AI-native development, memory banks are your organization's immune system—they prevent bad patterns from recurring. Specs are your surgical instruments—they solve specific problems precisely. Confusing the two is like using a scalpel when you need a vaccine, or vice versa.
Practice: Write Your First Spec
Now it's your turn. You're going to write a specification for a simple Python feature: exporting data from a Python list to a CSV file.
This is manual work — no AI, no templates, just you and clarity of thought.
Your Assignment
Create a spec.md file with these sections:
1. Intent (1-2 sentences)
- What problem does this solve?
- Why is it important?
2. Success Criteria (4-5 bullets)
- Each should be testable
- Think: "How will I know this works?"
3. Constraints (2-3 bullets)
- What must always be true?
- What limits our implementation?
4. Non-Goals (1-2 bullets)
- What's intentionally NOT included?
- What can wait for v2?
Example Structure (for reference)
# Specification: CSV Data Exporter
## Intent
Applications need to export Python data structures (list of dicts) to CSV files for sharing with non-technical users or importing into spreadsheet applications.
This improves usability by allowing data to be opened in Excel, Google Sheets, or other tools.
## Success Criteria
- Function export_to_csv(data: list, filename: str) writes data to valid CSV file
- CSV file can be opened in Excel/Google Sheets without errors
- Column headers match dict keys from first row
- Function handles special characters (commas, quotes) correctly
- Function preserves data types in output (numbers as numbers, not quoted strings)
## Constraints
- Must use only Python's built-in csv module (no external libraries)
- File encoding must be UTF-8 (supports international characters)
- CSV format must follow RFC 4180 standard (proper escaping, line endings)
- Must handle empty data lists gracefully (create valid empty CSV with headers)
## Non-Goals
- Custom delimiter support (comma-only for MVP)
- Excel .xlsx format (CSV only)
- Column sorting/reordering (use dict order)
- Data validation before export (caller validates data)
Self-Validation Checklist
After you write your spec, validate against the Quality Checklist for Specifications from the Quality Awareness section above:
Use These 5 Quality Questions:
- ✅ Clear Intent? (Section: Quality Awareness → Quality Checklist #1) — Can someone unfamiliar with the project understand the purpose in 30 seconds?
- ✅ Testable Success Criteria? (Section: Quality Awareness → Quality Checklist #2) — Could you write a pytest test that verifies each criterion?
- ✅ Explicit Constraints? (Section: Quality Awareness → Quality Checklist #3) — Are all edge cases and "what if...?" questions answered?
- ✅ Prevents Scope Creep? (Section: Quality Awareness → Quality Checklist #4) — Can you point to Non-Goals and defer future features?
- ✅ No Ambiguity? (Section: Quality Awareness → Quality Checklist #5) — Could two developers implement this independently with identical behavior?
Common Pitfalls to Avoid: Reference the pitfalls from Quality Awareness section:
- ❌ Vague language ("save properly" → "save to JSON with UTF-8 encoding")
- ❌ Missing edge cases ("export data" → "handle empty lists, special characters")
- ❌ Over-specification (don't specify algorithm, specify intent)
- ❌ Conflating spec with implementation (WHAT, not HOW)
- ❌ Forgetting why (include rationale for constraints)
Validation Protocol: For each criterion that's vague or missing, rewrite using the good spec vs bad spec examples from the Good Specs vs Bad Specs Comparison section (Quality Awareness → Part 3).
🤝 Practice Exercise
Exercise 1 (10-15 minutes): Write your spec for CSV exporter using the structure above.
Exercise 2 (5 minutes): Review your spec against the Self-Validation Checklist above. Rewrite any sections that are vague or unclear.
Exercise 3 (Reflection): Compare your spec to the configuration file manager example earlier. What did you do well? What could be clearer?
Exercise 4 (Quality Checklist Validation): Use the 5 Quality Questions from the Self-Validation Checklist to validate your CSV exporter spec:
- Does it answer "Clear Intent?" clearly and concisely?
- Are all Success Criteria testable (could you write pytest tests)?
- Are Constraints explicit with edge cases covered (empty lists, special characters)?
- Does Non-Goals section prevent scope creep?
- Is there any ambiguity? Could another developer implement identically?
For each criterion that fails, rewrite using the Good Specs vs Bad Specs patterns from Quality Awareness section.
Try With AI
Now that you've written your own spec manually, you're ready to explore how AI can help refine specifications. In Lesson 3, you'll see AI as a collaborative partner for spec improvement. But first, test your understanding with these prompts:
🔍 Evaluate a Vague Spec:
"Here's a feature request: 'Make the app faster.' Rewrite this as a complete specification with Intent, Success Criteria, Constraints, and Non-Goals. What questions did I need to answer to make this specific?"
🎯 Distinguish Specs from Memory Banks:
"I'm building a payment system. Is each of these a spec or memory bank rule? (1) 'All passwords must use bcrypt' (2) 'Payment checkout should support credit cards and PayPal' (3) 'API endpoints require JWT authentication' (4) 'Add a refund feature for disputed transactions.' Explain your reasoning."
🧪 Test Your Spec Quality:
"Review this spec I wrote: [paste your CSV exporter spec from the practice exercise]. Is there any ambiguity? What success criteria could be more specific? What constraints am I missing?"
🚀 Apply Evals-First to Your Work:
"I'm working on [describe a feature you need to build]. Help me write the Success Criteria section first, before I think about implementation. What would make this feature clearly 'done'?"